Chapter 4 Open Worldwide Application Security Project (OWASP)
The Open Worldwide Application Security Project (OWASP) is a nonprofit foundation that works to improve the security of software [6].
One of OWASP’s best-known projects is the Top 10 - a list of the ten most significant vulnerabilities. This list is updated every two to three years due also to changing threats and attack opportunities. While classically OWASP was focused on software, new in recent months is the inclusion of specific vulnerabilities and challenges to AI systems. As a result we get two new lists of top 10 vulnerabilities. OWASP Machine Learning Security Top Ten focused on the security of ML systems and OWASP Top 10 for Large Language Model Applications [7] focused on systems using large language models (LLMs). In April 2024 this list got extended with LLM AI Cybersecurity & Governance Checklist [8].
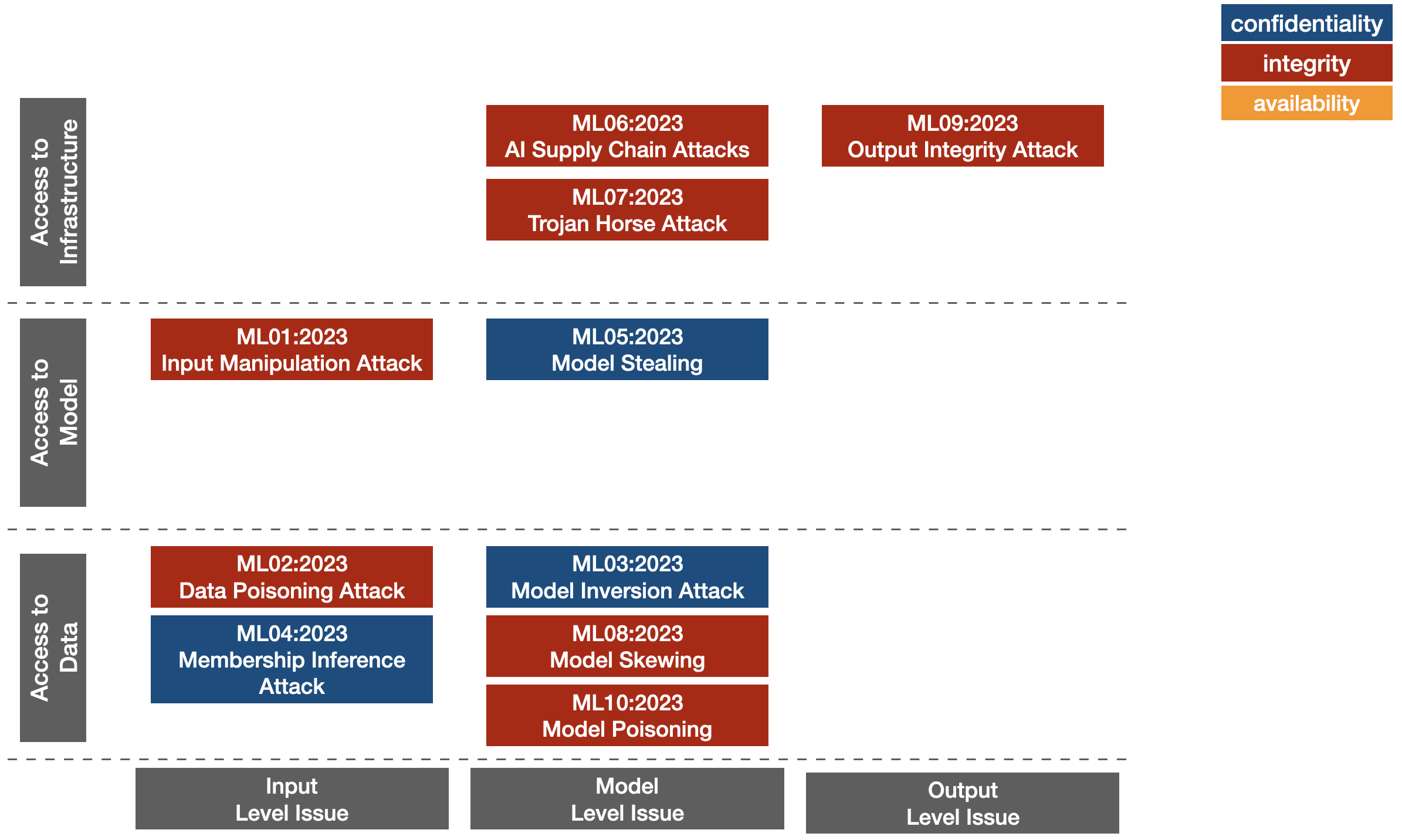
Below we briefly overview the Top 10 for Machine Learning Security.
Note The list presented is still available as a draft version. Some positions are quite similar and perhaps the final Top 10 will be a little different. The following list is an abridged summary. The full version can be found at https://mltop10.info/.
4.1 ML01:2023 Input Manipulation Attack
Attacks involving data manipulation, including adversarial attacks. In this scenario the attacker deliberately changes the input data to alter the model’s decisions. For example, for a model that detects the presence of a person, the attack might involve developing a special stamp whose presence causes the person to go undetected.
Example mitigation strategies
Adversarial training One approach to defending against input manipulation attacks is to train the model on adversarial examples.
Input validation Checking input data for anomalies, such as unexpected values or patterns, and rejecting input data that may be malicious.
4.2 ML02:2023 Data Poisoning Attack
Attacks involving data poisoning occur when an attacker manipulates training data to cause unwanted model behavior.
Example mitigation strategies
Model validation Validate the model using a separate validation set that was not used during training. This can help detect any data poisoning attacks that may have affected the training data.
Anomaly detection Using anomaly detection techniques to detect any unusual behavior on the network.
4.3 ML03:2023 Model Inversion Attack
Attacks involving model inversion occur when an attacker reverse-engineers a model to extract information from it, such as regarding the training set (checking if any observation was in the training data).
Example mitigation strategies
Access control Restricting access to the model or its predictions (authentication) can prevent attackers from obtaining the information needed to reverse engineer the model.
Regular monitoring Monitoring the model’s predictions for anomalies can help detect and prevent model inversion attacks (tracking the distribution of input and output data).
4.4 ML04:2023 Membership Inference Attack
Attacks involving membership inference occur when it analyzes model inferencing to see what data was in the training data, if specific observation was used in the training data.
Example mitigation strategies
Model obfuscation Obfuscating model predictions by adding random noise or using differential privacy techniques.
Regularization, such as L1 or L2 regularization, can help prevent over-fitting the model to the training data, which can reduce the model’s ability to accurately determine whether an example is included in the training data set.
4.5 ML05:2023 Model Stealing
Attacks involving model stealing occur when an attacker gains access to model parameters and is able to accurately reproduce the model’s behavior on new data.
Example mitigation strategies
Watermarking Adding a watermark to model code and training data can make it possible to trace the source of the theft and hold the attacker accountable.
Encryption Encrypting model code, training data and other sensitive information can prevent attackers from accessing and stealing the model.
4.6 ML06:2023 AI Supply Chain Attacks
Attacks involving a modified AI supply chain occur when an attacker modifies or replaces a library or machine learning model that is used by the system. This can also include data associated with machine learning models.
Example mitigation strategies
Use package verification tools Such as PEP 476 and Secure Package Install to verify the authenticity and integrity of packages before installing them.
Use secure package repositories, that enforce strict security measures and have a package verification process.
4.7 ML07:2023 Troyan Horse Attack
Attacks involving transfer learning (aka Troyan horse attacks) occur when an attacker trains a model in one task and then tunes it in another task to cause it to behave in an undesirable way.
Example mitigation strategies
Implement model isolation can help prevent the transfer of malicious knowledge from one model to another.
Using secure and trusted training datasets can help prevent the transfer of malicious knowledge from the attacker model to the target model.
4.8 ML08:2023 Model Skewing
Attacks involving model skewing occur when an attacker manipulates the distribution of new training data to cause the model to behave in undesirable ways.
Example mitigation strategies
Verify the authenticity of feedback data digital signatures and checksums may be useful to verify that the feedback data received by the system is authentic, and discard any data that does not match the expected format.
Regularly monitor model performance and compare its predictions with actual results to detect any deviations or distortions.
4.9 ML09:2023 Output Integrity Attack
Attacks on Output Integrity aim to modify or manipulate the output of a machine learning model in order to alter its behavior or cause harm to the system in which it is used.
Example mitigation strategies
Secure communication channels between the model and the interface responsible for displaying results should be secured using secure protocols such as SSL/TLS.
Input validation should be performed on the results to check for unexpected or manipulated values.
4.10 ML10:2023 Model Poisoning
Attacks involving model poisoning occurs when an attacker manipulates model parameters to cause undesirable behavior.
Example mitigation strategies
Regularization Adding regularization techniques, such as L1 or L2 regularization, to the loss function helps prevent over-fitting and reduces the risk of model poisoning attacks.
Cryptographic techniques can be used to secure model parameters and weights and prevent unauthorized access or manipulation of these parameters.